
3 Things Every Data Scientist Should Know
Table of Contents
Being a data scientist is hard. People expect you to do everything, and because the subject is much younger than other software related fields, the best practices aren't as well-developed yet. I thought it might be a good idea to write down 5 things I find key in doing good data science and that might help you on your journey.
1 Write down everything!
Data Science is a game of knowledge. Every working day you gather more knowledge and add it to the pile.
But if it is not documented, knowledge gets forgotten quickly and you're bound to repeat experiments again and again, because you don't know exactly what the result was last time.
This can be done with an excel-sheet, confluence or even a piece of paper, but there exist experiment tracking tools like MLFlow or Tensorboard, where you set up that the parameters and results of your experiments are written to some central place, and you'll be able to look up past results easily.
But this is not enough. Soon you'll have more experiments lying around than you can count, and you wouldn't be able to find anything, even if you tried. You have to clean up your space regularly and add descriptions and conclusions to your experiments. This way, it will feel like a library you can always come back to.
2 Make experiments fast!
At the very start of a new project it makes sense to start working on some data in a notebook and see what you can do with it. But quickly you might notice that you have 12 notebooks lying around, all copying code from one another and each time you want to try something new, it takes ages because you need to find the code you need and stick it together like Frankensteins monster.
At this point (or ideally before it comes this far) it makes sense to stop and consolidate your experiment setup. Write a python script that runs through your Analysis or Model Training start to finish and produces all relevant results. Push it to git-hub. Maybe even containerize it, so you can run many experiments at the same time.
Now your experimenting setup becomes:
- Change 1 small detail in teh experiment
- Run The experiment
- Store Results
You see it has become really easy to run experiments, and since the results are standardized, it becomes really easy to compare runs. If it sounds too easy, it is.... but I myself fell down the trap of not doing this soon enough many times.
3 Insights are products too!
I hear Data Science being conflated with "AI model building" way too often. It is not. Sometimes AI models are a path towards what the company actually wants: knowledge, but very often it is also not.
Sometimes a good visualization, a dashboard or a statistical analysis can provide way more value than your model, even if it worked the way you promised in the beginning. (Sorry)
Don't just assume the solution to every problem being a model. First try to learn as much about your data, try to gain insights. One sentence in a presentation could transform the whole business.
If the knowledge the stakeholders are looking for is not as simple, maybe a dashboard on past data might help. Talk to your stakeholders often. They know much better than you what they need.
Of course often you do end up needing some kind of model, but don't be the hammer that sees everything as a nail.
4 Visualization is Key
Your stakeholders are likely not statisticians. This means in order for your groundbreaking discovery to fall an fertile ground, you need to do more than to present them with more than a p-value of 10e-100 you need to show them something that is simple to understand and clearly shows the effect you proved exists.
This is an art form, and way harder than you might initially think. Just throwing your data into your favorite plotting library and presenting the first plot you could think of will probably not cut it.
My favorite example for this is the plot that was published by the LHC Atlas team to show that the Higgs particle was discovered. The underlying physics would take very long to explain, but any laymen can look at the plot and immediately see "There's a bump there!" Which is the one important information the plot aims to convey. ()
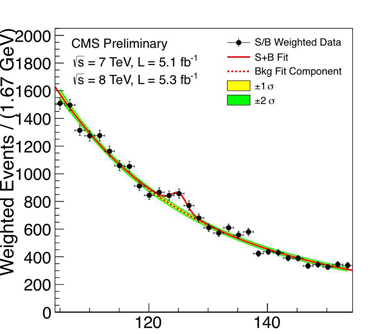
(source: https://higgs.ph.ed.ac.uk/higgs/)
This is not the place to do a deep dive. But here are a few rules I like to follow: 1. Your plot should show exactly one thing. 2. Reduce complexity. Scatter plots are great for initial EDA, but if you discovered something it makes much more sense to present it in a isolated histogram. 2. Give context (It doesn't tell me anything that the temperature today is 20C without the context that last year it was 10C) 3. Take time labelling your axes and legend with meaningful names and Units. 4. No 3D plots .... EVER! (Sorry ... not sorry)
Do not neglect visualization by focussing only on the machine learning part of data science. Statistics and visualization is the foundation everything else is built on. Remove them and any ML work you do becomes worthless.
5 Gather Domain Knowledge
I blame this one on the name "Data Scientist". Every scientist is working with data, but you are working in a specific field. Maybe you work for a telecommunications company making you a "Telecommunications Scientist" or you could be a "Sales Scientist" somewhere else. This broad label exists in no other field. No one would hire an Mechanical Engineer to build a highrise building, you want a civil engineer for that.
It's easy to tell yourself 'I don't need to understand the underlying domain, I'll simply work with the data I get' But you'd be wrong. Your domain existed way before our profession was invented, and people used scientific methods to optimize the business already back then.
It is worth getting to know how everything in your domain works, and why things are done the way they are. Instead of starting from nothing, you instead build on a large set of knowledge build up by your predecessors. This will help enourmeously in interpreting your results, selecting features and understanding the limitations of your work.
Learn as much as you can from your non-Data Science collegues and thank me later.